Este proyecto fue desarrollado como proyecto final del Magíster en Ciencia de Datos de la Pontificia Universidad Católica de Chile, y logró la máxima calificación. Su objetivo fue ambicioso: predecir cuántos nuevos casos de cáncer podrían diagnosticarse en Chile entre 2020 y 2024, usando modelos de machine learning como LightGBM, Random Forest, XGBoost y otros.
Los datos utilizados provienen de seis Registros Poblacionales de Cáncer (RPC), junto con información del Ministerio de Salud, el Instituto Nacional de Estadísticas y la Agencia Internacional de Investigación en Cáncer (IARC). A partir de estos datos, los investigadores construyeron una base que cubre más del 20% de la población chilena, suficiente para generar proyecciones representativas a nivel nacional.
¿Qué compartieron los invitados en el podcast?
Durante la conversación con Camilo Martínez Zambrana, anfitrión del podcast y director de proyectos en Red PandaLab, los autores compartieron:
✅ El proceso técnico detrás del modelo: limpieza de datos, imputación, selección de algoritmos y validación. ✅ Los retos metodológicos, como la falta de datos nacionales consolidados y la necesidad de imputar valores faltantes. ✅ Cómo la combinación de regresión de Poisson y regresión lineal superó en precisión a modelos más complejos de machine learning. ✅ El impacto de contar con estimaciones actualizadas en la planificación de recursos de salud, desde camas oncológicas hasta estrategias de prevención.
Además, los invitados hablaron de su trayectoria y cómo sus habilidades en ciencia de datos se aplican hoy en diferentes sectores.
¿Por qué es relevante esta investigación?
Chile no cuenta aún con un registro nacional de cáncer, lo que dificulta tomar decisiones informadas. Esta investigación llena un vacío crítico al proporcionar proyecciones basadas en evidencia, utilizando datos reales y técnicas avanzadas.
Los resultados no solo ofrecen una mirada a futuro sobre la incidencia del cáncer, sino que también sirven como modelo para otras investigaciones que buscan aplicar ciencia de datos en salud pública.
Algunas proyecciones clave para 2024:
Se estima que Chile tendrá más de 41.000 nuevos casos de cáncer.
Las regiones con mayor incidencia proyectada incluyen Los Ríos, Metropolitana y Maule.
Escucha el episodio
🎙️ Dale play al episodio completo aquípara conocer de primera mano cómo esta investigación puede cambiar la manera en que planificamos y respondemos al cáncer en Chile.
Sobre Café+Data
Café+Data es una iniciativa de Red PandaLab, donde compartimos experiencias, proyectos y aprendizajes del mundo de los datos. Además de nuestros podcasts, organizamos webinars, talleres y espacios de formación.
💡 Si te interesa aplicar los datos a problemas reales como este, suscríbete a nuestra comunidad o revisa nuestros próximos eventos.
Te invitamos a revisar nuestro último “Café+Data” donde hablamos sobre Python.
En esta sesión Eduardo Zevallos nos introdujo a Python llevándonos desde la simple creación de una variable hasta la publicación de una aplicación realizada con Python.
En este blog te mostraremos algunos de los usos que podés darles a las bases de datos Open Buildings de Google. En concreto trabajaremos con las bases de datos para Nicaragua, obteniendo como resultado final una base de datos de edificaciones a nivel de departamentos y municipios (ciudades). En este blog usaremos las edificaciones como variable de aproximación (proxy) al concepto de infraestructura.
Algunos de los usos que puedes darle a la base de datos final incluye estimaciones poblacionales, identificación de centros urbanos y zonas de riesgo entre muchas otras.
Realizamos el proceso utilizando Python en un Jupyter Notebook y te lo mostraremos paso a paso. Las bases de datos que utilizamos y las resultantes te las dejamos por acá:
Open Buildings es una iniciativa de Google que pone a disposición del público un conjunto de datos abiertos a gran escala que contienen contornos de los edificios detectados a través de imágenes satelitales de alta resolución. El dataset contiene 1.8 billones de detecciones de edificios para una superficie de 58 millones de km2. La imágenes corresponde al año 2021, en algunos casos el año de la detención puede variar.
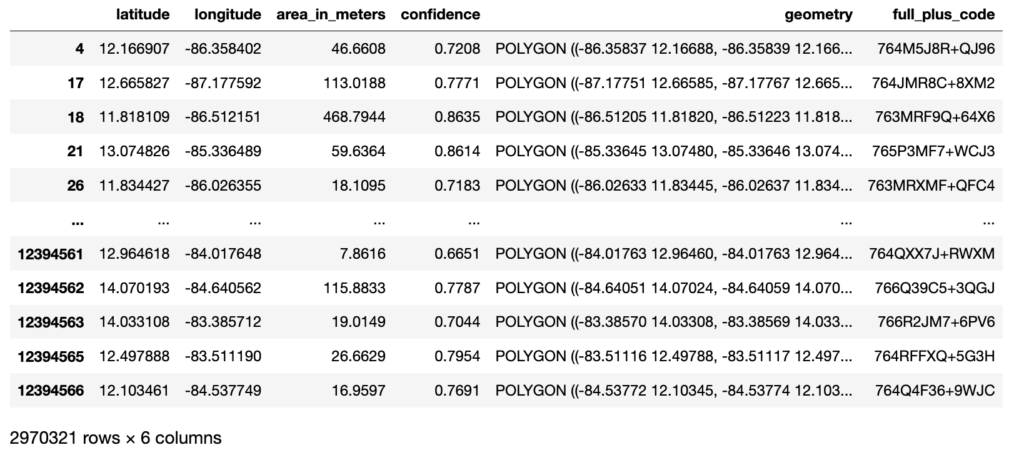
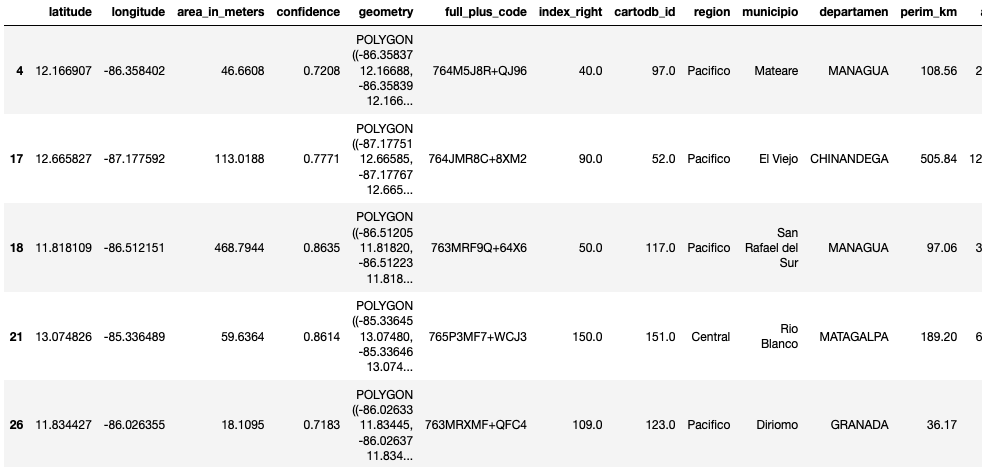
Al descargar un dataset las variables incluidas son:
latitude: Latitud en grados decimales del centroide del polígono.
longitude: Longitud en grados decimales del centroide del polígono.
area_in_meters: Área en metros cuadrados del polígono.
confidence: Puntuación de confianza que indica la certeza de que sea una edificación, este valor varía de 0.65 a 1.
geometry: Representación del polígono de la edificación en formato WKT.
full_plus_code: Ubica un punto en el centro de la edificación.
¿Qué se entiende por “edificaciones o edificios” en el contexto de los datos?
El término edificio y edificación se usará como sinónimo, y se refiere a estructuras construidas que tienen una ubicación y huella física.
Proceso
A continuación te explicamos los código que utilizamos, pero primero, te vamos a contar de forma general los que hicimos para que tengas un poco de contexto del proceso.
Como mencionamos anteriormente el resultado de este código es una base de datos de edificaciones a nivel de departamentos y municipios de Nicaragua. Lo primero que debemos hacer es instalar todas las librerías de Python que usaremos.
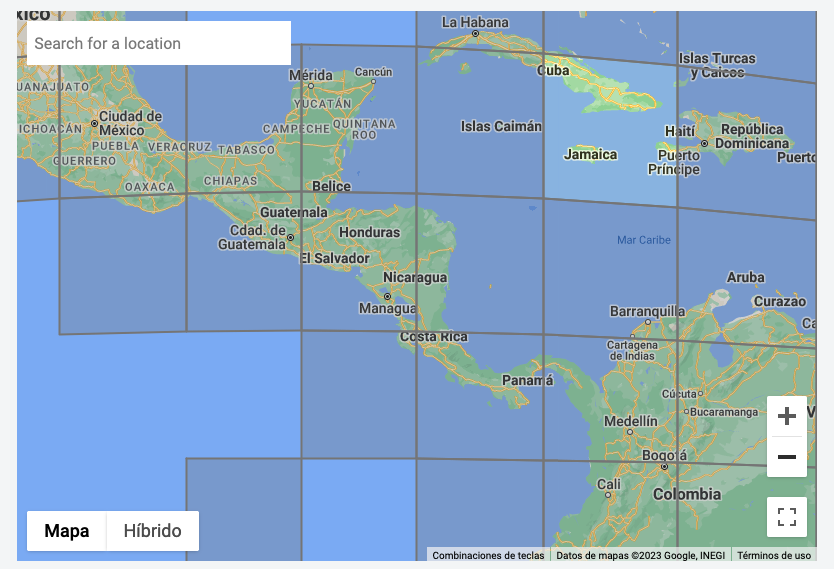
Luego debemos descargar las bases de datos correspondientes a Nicaragua. Para esto debemos ir a Open Buildings y en el apartado “Download from the map” seleccionar los cuadrantes que corresponde a Nicaragua. Cada cuadrante es una base de datos, y para el caso de Nicaragua fue necesario descargar los datos de dos cuadrantes que luego debemos unir (los CSV pesan 110mb y 3gb). En la imagen 1 te mostramos cuales son estos cuadrantes. Como podés observar, en los cuadrantes donde está Nicaragua, también está Honduras, El Salvador, parte de Guatemala, Belice y Costa Rica. Esto significa que debemos limpiar la base de datos. Una vez que hemos dejado solo a Nicaragua, cruzaremos esta base de datos con los polígonos de cada municipio del país, y obtendremos una nueva base de datos con las variables de departamento y municipio. Para lograr estos hay que hacer algunas transformaciones de variables y verificaciones que ya te explicaremos en el código, pero en general ese es el sencillo proceso que hemos realizado.
Imagen 1. Descarga de bases de datos desde el mapa.
Una vez que obtengamos la base de datos GIS final, podrás conocer la cantidad de edificaciones por departamento y municipios (en metros cuadrados y en cantidades), y cruzar con otras bases de datos.
Código
El siguiente código fue escrito y ejecutado en un Jupyter Notebook, con Python versión 3.9.12.
El código mostrado a continuación está acompañado por comentarios explicando los procesos a realizar. Este código está listo para que lo copies y pegues en tu Jupyter Notebook y podás seguir el proceso.
El código lo dividiremos en tres etapas:
Etapa 1: Importación de librerías, base de datos a utilizar y transformación de variables.
Etapa 2: Importación de polígonos de los municipios y transformación de variables.
Etapa 3: Unión de DataFrames.
Etapa 1: Importación de librerías, base de datos a utilizar y transformación de variables.
# Importando las librerías a utilizar
pip install geopandas
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import geopandas as gpd
from shapely.geometry import Point
from shapely import wkt
from shapely import wkb
from shapely.wkt import loads
import shapely.wkt
import binascii
# Importando los dos archivo CSV correspondientes a los dos poligonos que ubican a Nicaragua y convirtiéndolos a dataframes de Python. Estos son los dos cuadrantes de la imagen 1.
df0 = pd.read_csv('8f7_buildings.csv')
df1 = pd.read_csv('8f1_buildings.csv')
# Uniendo los dos datraframes
df = pd.concat([df0, df1]).reset_index(drop=True)
df.head()
# Convirtiendo la columna de geometría de strings a objeto Polygon
df['geometry'] = df['geometry'].apply(shapely.wkt.loads)
# Convirtiendo el dataframe "df" a un GeoDataFrame
gdf = gpd.GeoDataFrame(df, geometry='geometry')
# Obteniendo el polígono de Nicaragua
# Importando librería que permite obtener datos geográficos de OpenStreetMap (OSM), y para este caso obtener las fronteras administrativas de Nicaragua.
import osmnx as ox
# Usando osmnx para obtener el polígono de Nicaragua.
nicaragua = ox.geocode_to_gdf('Nicaragua')
# GeoDataFrame cuenta con una sola fila, entonces seleccionamos el primer polígono.
polygon = nicaragua['geometry'][0]
# Filtramos los datos para obtener solo la información de Nicaragua. Esto puede tomar entre 2 a 4 horas dependiendo de la capacidad de tu computadora.
gdf_nic = gdf[gdf.geometry.within(polygon)]
gdf_nic
# Guardando el dataframe de Nicaragua en formato CSV.
gdf_nic.to_csv('gdf_nic.csv')
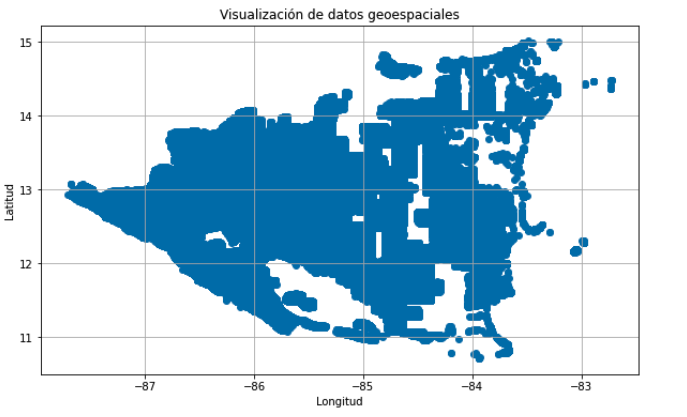
# Graficando para tener una visualización espacial de los datos. Esto lo hacemos para saber como se distribuyen espacialmente las edificaciones.
plt.figure(figsize=(10, 6))
plt.scatter(gdf_nic['longitude'], gdf_nic['latitude'])
plt.xlabel('Longitud')
plt.ylabel('Latitud')
plt.title('Visualización de datos geoespaciales')
plt.grid(True)
plt.show()
Etapa 2: Importación de polígonos de los municipios y transformación de variables.
# Importando la base de datos para extraer los polígonos de los municipios. Esta base de datos te la hemos compartido al inicio de este tutorial.
muni = pd.read_csv('municipios_nic.csv')
# Transformación de la variables "the_geom" (WKB (Well-Known Binary)) a formato shapely.geometry.
muni['the_geom'] = muni['the_geom'].apply(lambda x: wkb.loads(binascii.unhexlify(x)))
# Convirtiendo el dataframe muni a formato GeoDataFrame
gdf_muni = gpd.GeoDataFrame(muni, geometry='the_geom')
# Verificando que gdf_nic sean GeoDataFrame para poder unirlos. Esto lo podríamos omitir, pero siempre es importante verificar.
if isinstance(gdf_nic, gpd.GeoDataFrame):
print("df es un GeoDataFrame")
else:
print("df no es un GeoDataFrame")
# Verificando que gdf_muni sean GeoDataFrame
if isinstance(gdf_muni, gpd.GeoDataFrame):
print("df es un GeoDataFrame")
else:
print("df no es un GeoDataFrame")
Etapa 3: Unión de DataFrames.
# Unión de gdf_nic y gdf_muni
# Cambiando el nombre de la variable "the_geom" a "geometry" en gdf_muni.
gdf_muni = gdf_muni.rename(columns={'the_geom': 'geometry'})
# Definiendo la variables "geometry" como la columna de geometría activa.
gdf_muni = gdf_muni.set_geometry('geometry')
# Uniendo las bases de datos realizando un spatial join.
gdf_nic_muni = gpd.sjoin(gdf_nic, gdf_muni, how="left", op='intersects')
# La base de datos cuenta con 2,973,301 edificaciones identificadas para Nicaragua.
gdf_nic_muni
# Guardando el GeoDataFrame de edificaciones de Nicaragua a nivel de municipios en formato CSV. Podés descargar esta base de datos al inicio de este tutorial.
gdf_nic_muni.to_csv('gdf_nic_muni.csv')
Hasta aquí ya hemos creado la base de datos de edificación para Nicaragua a nivel de municipios. Ahora toca hacer un análisis exploratorio de los datos para identificar valores atípicos, nulos, inconsistencias entre otros. A continuación mostramos el código que nos permite identificar los valores nulos.
# Identificación de registros/edificaciones que cuentan con valores nulos.
gdf_nic_muni[gdf_nic_muni['index_right'].isna()]
Identificamos 8,018 registros con valores nulos. Estos datos corresponden a registros que no encontraron correspondencia con los polígonos de los municipios. Para corregir estos valores nulos podemos ir a cada ubicación e identificar el municipio correspondiente, este proceso puede que sea muy tardado. En nuestro caso eliminaremos los registros que contengan valores nulos y todos aquellos que tengan puntuación de confianza (confidence) menor a 0.7, luego mostraremos el ranking de los municipio con mayor “infraestructura” en Nicaragua. Para este ejemplo, entenderemos el área de las edificaciones como una variable proxy a la infraestructura del municipio.
# Eliminando registros/edificaciones que contengan valores nulos en cualquiera de las columnas
gdf_nic_muni = gdf_nic_muni.dropna()
# Obteniendo solo los registros/edificaciones con puntaje menor a 0.7.
gdf_nic_muni_07 = gdf_nic_muni[gdf_nic_muni['confidence'] >= 0.7]
# Obteniendo dataframe de los municipios por área de edificaciones en metros cuadrados.
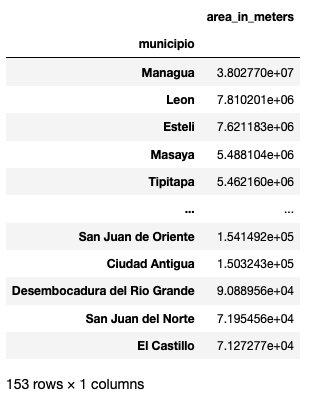
gdf_nic_muni_07_agrupado=gdf_nic_muni_07[['municipio','area_in_meters']].groupby('municipio').sum()
gdf_nic_muni_07_sorted=gdf_nic_muni_07_agrupado.sort_values('area_in_meters', ascending=False)
gdf_nic_muni_07_sorted
Como podemos observar los tres municipios con mayor infraestructura (área de edificaciones) es Managua, León y Esteli, por otro lado los que cuentan con menor infraestructura son El Castillo, San Juan del Norte y Desembocadura del Rio Grande.
Sin embargo, para hacer un ranking más justos seria necesario comparar el área de edificaciones y el área del municipio. Esto lo hacemos en el siguiente código:
# Convirtiendo hectarias y metros cuadrados a kilometros cuadrados.
gdf_nic_muni_07_agrupado['area_in_km2_muni'] = gdf_nic_muni_07_agrupado['area_ha']/100
gdf_nic_muni_07_agrupado['area_in_km2_edi'] = gdf_nic_muni_07_agrupado['area_in_meters']/1000000
# Encontrando la relación entre el área de edificación y el área del municipio.
gdf_nic_muni_07_agrupado['relacion_edi_muni'] = gdf_nic_muni_07_agrupado['area_in_km2_edi']/gdf_nic_muni_07_agrupado['area_in_km2_muni']
gdf_nic_muni_07_agrupado['m2_de_edi_por_1km_de_muni'] = gdf_nic_muni_07_agrupado['relacion_edi_muni']*1000000
# Ordenando por la variable "m2_de_edi_por_1km_de_muni". Esta variables lo que muestra el área de edificación en metros cuadrados por cada 1 kilometros cuadrado de área en el municipio.
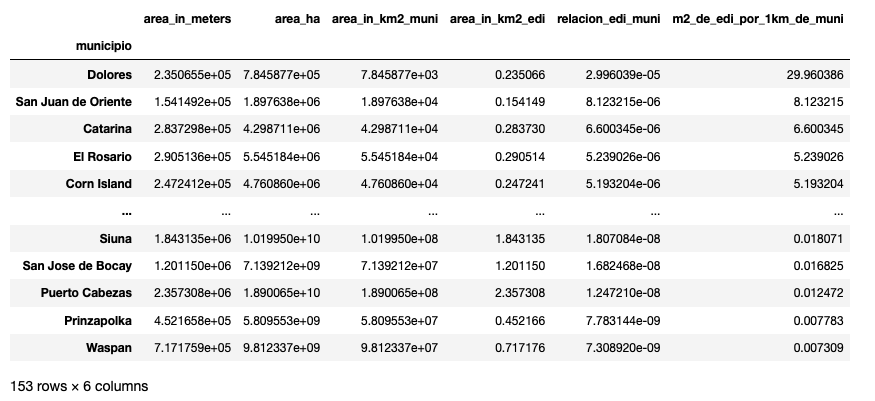
gdf_nic_muni_07_agrupado_sorted = gdf_nic_muni_07_agrupado.sort_values(by='m2_de_edi_por_1km_de_muni', ascending=False)
gdf_nic_muni_07_agrupado_sorted
Con este resultado el ranking cambia completamente, y podemos decir que el municipio de Dolores, cuenta con la mayor relación área de edificación y área del municipio. Para este municipio por cada kilometro cuadrado de área hay apróximadamente 30 metros cuadrados de edificación. Los municipios con menor relación son Puerto Cabezas, Prinzapolka y Waspan.
Hasta aquí llegamos con este tutorial, y como te estarás imaginando, las aplicaciones con esta base de datos son muchísimas, algunos de los posibles usos pueden ser la identificación de los centros urbanos, conteo de viviendas en zonas rurales, edificaciones cerca de zonas de riesgo, entre otros.
Te compartimos la grabación de nuestro último “Café+Data Session” sobre el uso de encuestas digitales en la investigación social, donde hablamos de la herramienta KoboToolbox y las ventajas que esta ofrece.
Si quieres conocer cómo KoboToolbox se puede integrar en tu empresa u organización, contáctenos.
KoboToolbox es una herramienta de recopilación de datos de código abierto que permite diseñar encuestas, recolectar y analizar datos, es especialmente utilizado en la recolección de datos en zonas remotas o de difícil acceso. KoboToolbox se caracteriza por ser una herramienta de fácil uso e intuitiva, que permite escalar proyectos de datos, desde simples encuestas para uso interno de una organización hasta proyectos nacionales o regionales de recolección de datos. El uso de Kobo se ha extendido en distintos campos de investigación, incluyendo salud, educación, infraestructura, economía, estudios de opinión, conservación ambiental, entre otros.
En el campo de la conservación ambiental, KoboToolBox ha sido una herramienta eficiente y confiable en los procesos de recolección de datos. A continuación, se muestran algunos ejemplos del uso en proyectos de conservación:
Monitoreo de la salud de los ecosistemas
La herramienta puede ser utilizada en la recolección de datos sobre vegetación, suelo, clima, fauna y otros aspectos del ecosistema. Una función relevante en este aspecto es la opción de georreferencias, que permiten obtener datos de ubicación, también es posible crear polígonos para referenciar aéreas del terreno.
El Instituto de Investigación de la Amazonía Peruana (IIAP) utiliza KoboToolbox para recopilar y analizar datos sobre la biodiversidad en la Selva Amazónica. El objetivo es evaluar la salud de los ecosistemas y detectar cambios a lo largo del tiempo.
Evaluación de impacto de actividades humanas
KoboToolBox puede ser utilizada para el registro de las actividades como la tala de árboles, agricultura, minería y urbanización. Una función útil es este aspecto es la opción de tomar una fotografía con el smartphone o tablet con el que se está recolectando información, esto podría ayudar a crear una línea de tiempo fotográfica de la evolución de la actividad con referencia geográfica del sitio donde se tomó la foto.
La organización World Resources Institute (WRI) utiliza KoboToolbox para recopilar y analizar datos sobre la tala de árboles en Indonesia.
Monitoreo de especies
Las organizaciones utilizan KoboToolbox para recopilar datos sobre la presencia, distribución y población de especies. Estos datos se utilizan para evaluar la salud de las poblaciones de especies y detectar cambios a lo largo del tiempo. Una función útil en esto es la agregación de datos dinámicos (dynamic data attachmens), lo que permite agregar información en distintos momentos del tiempo a la misma unidad de análisis, por ejemplo, si estamos monitoreando la salud de animales con identificadores únicos.
La organización Invasive Species Council (ISC) utiliza KoboToolbox para recopilar y analizar datos sobre la presencia de especies invasoras en Australia. El objetivo es evaluar la salud de las especies y detectar cambios a lo largo del tiempo.
Evaluación y seguimiento
KoboToolbox es una excelente herramienta para la evaluación y seguimiento proyectos. Esto es especialmente relevante para la obtención de datos que ayuden a evidenciar las buenas y malas prácticas de los procesos, con el fin de mejorar las intervenciones. Algunas opciones relevantes son la grabación de sonido y video directo, esto puede ser útil a la hora de registrar testimonios de personas involucradas en el proyecto, así como para tener un registro audiovisual de las zonas de interés de los proyectos.
El ICRAF utiliza KoboToolbox para recopilar y analizar datos sobre el uso de la tierra, la biodiversidad y el impacto ambiental de las prácticas agrícolas en África. Utilizan el sistema para registrar información sobre el tipo de cultivos que se están plantando, el uso de fertilizantes y pesticidas, y los patrones de uso del suelo. También utilizan el sistema para evaluar el impacto de las prácticas agrícolas en la biodiversidad y el medio ambiente, y para identificar áreas de riesgo donde las prácticas agrícolas podrían estar dañando el medio ambiente.
Estas son tan solo algunas aplicaciones en proyectos de conservación ambiental. KoboToolbox puede ir mucho más allá de los aquí descrito. Te invitamos a conocer más de esta herramienta gratuita y de código abierto en: https://www.kobotoolbox.org/
Si querés conocer más sobre las funciones de KoboToolbox, podés contactar el equipo de Red Panda Lab y con gusto te haremos una presentación y te contaremos nuestra experiencia con la herramienta.